Contact Information
- Email: miyah.segura1@gmail.com
- LinkedIn: Miyah Segura
- GitHub: GitHub Profile
About Me I am a data-driven professional with a Master’s in Data Science and 5+ years of experience in data analysis, system integration, and workflow automation. My expertise spans across SQL, Python, Power BI, and cloud-based platforms, allowing me to develop scalable solutions that drive business insights and efficiency. This portfolio showcases my data science projects, highlighting my technical skills and problem-solving approach.
Projects

1. Angel Number Identifier Web App
Key Achievements: Gained significant engagement from the spiritual community and successfully deployed the app using Render.
Tech Stack: Python (Flask), HTML/CSS, OpenAI API, C#, SQL
Description: Built a web application that interprets angel numbers, providing users with spiritual insights based on numerical patterns. Implemented API calls to OpenAI for dynamic interpretations and integrated SQL databases for efficient data handling.
Try the Site: angelnumberidentifier.onrender.com
Github: Angel Number. PY File
2. Face Detection and Recognition Using Deep Learning
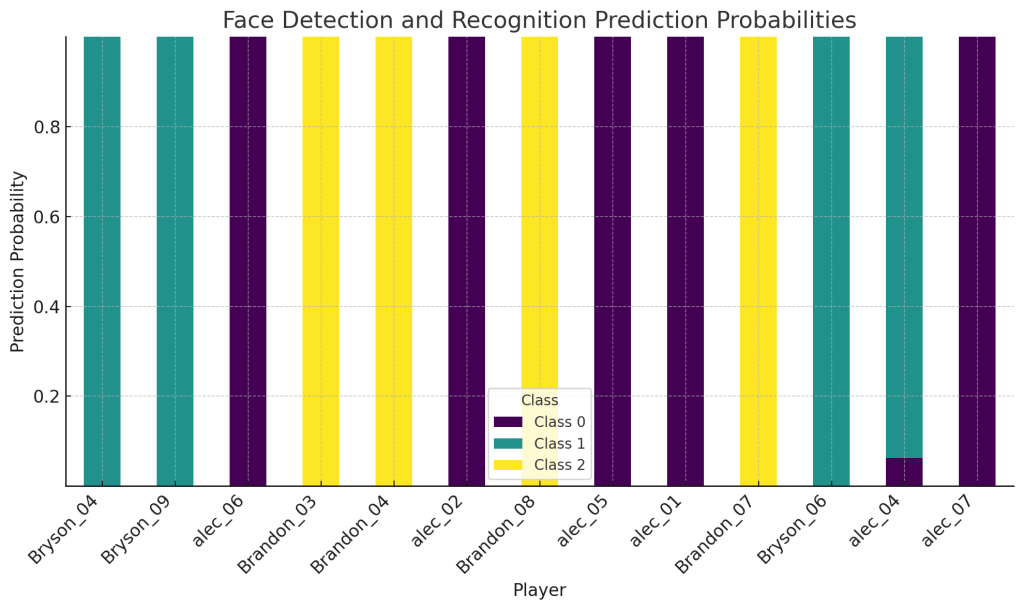

Overview:
This project applies Machine Learning and Computer Vision techniques to detect and recognize faces of baseball players from the 2024 Philadelphia Phillies. The dataset includes images extracted using the MTCNN face detection algorithm and processed using TensorFlow and Scikit-Learn.
Key Highlights:
✔ Face Detection: Used MTCNN to extract facial regions from images.
✔ Feature Extraction: Leveraged ResNet50 to obtain feature embeddings.
✔ Classification Model: Trained an SVM classifier to recognize individual players.
✔ Model Evaluation: Assessed classification performance using Precision, Recall, and F1-score.
✔ Deep Learning Integration: Implemented TensorFlow for image preprocessing and model training.
Technologies Used:
Data Processing: Image Preprocessing, Data Augmentation
Programming Languages: Python
Libraries & Frameworks: TensorFlow, OpenCV, Scikit-Learn, MTCNN
Machine Learning Models: SVM, ResNet50 Feature Extraction
Github: Face Detection Jupyter File
3. Unigram Language Model for Text Analysis

Overview:
This project focuses on building a unigram language model to analyze and predict word probabilities within a text corpus. The model was trained on Bram Stoker’s novel “Dracula”, using text preprocessing, tokenization, and frequency-based probability calculations.
Key Highlights:
✔ Text Preprocessing: Cleaned and tokenized text data by removing punctuation, stop words, and converting to lowercase.
✔ Unigram Model: Implemented a Maximum Likelihood Estimation (MLE) unigram model to predict word probabilities.
✔ Statistical Analysis: Calculated word frequency distributions and probability estimates.
✔ NLP Libraries: Utilized NLTK for text processing and modeling.
Technologies Used:
Data Processing: Tokenization, Stopword Removal, Frequency Analysis
Programming Languages: Python
Libraries & Frameworks: NLTK, NumPy, Pandas
Machine Learning Models: Unigram Language Model (MLE)
Github: Unigram Jupyter Notebook
